1. 参数规模与硬件需求
7B 模型
7B 模型参数数量较少,属于轻量级版本。由于参数规模较低,其内存和显存需求较为友好,适合在资源有限的设备或低配硬件上运行。对于大部分常规自然语言处理任务和一般推理场景,7B 模型能够在效率和效果之间取得较好的平衡。使用量化模型建议的显存:8G及以上。
14B 模型
相比 7B,14B 模型的参数量翻倍,意味着它能捕捉到更复杂的语言模式和更细粒度的推理信息。14B 模型在数学推理、代码生成以及专业领域的问答任务中通常会表现得更加出色。不过,由于参数增多,所需的硬件资源(如 GPU 显存和内存)也相应提高,因此在部署时需要选择配置稍高的设备。使用量化模型建议的显存:12G及以上。
32B 模型
32B 模型属于高端版本,参数数量达到数十亿级别,这使得模型拥有更强的表示能力和更高的精度,特别是在处理需要深入理解和长链推理的复杂任务上。尽管其性能明显优于 7B 和 14B,但高昂的计算资源需求(更大的显存和内存)也使得它更适合专业场景或服务器级别部署。使用量化模型建议的显存:24G及以上。
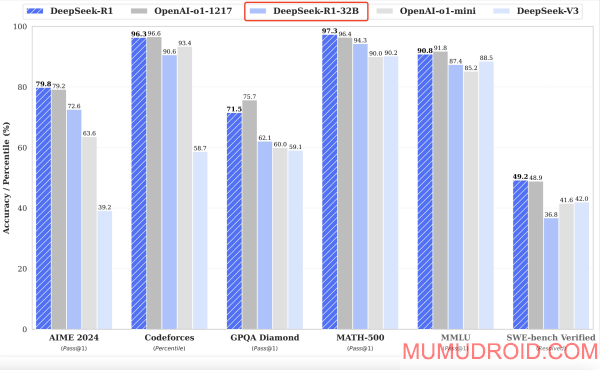
2. 性能表现与应用场景
7B 模型的特点
优势:响应速度快、部署成本低、运行效率高。适合实时对话、简单问答及资源受限的场景。
局限:在面对需要长链推理或极高准确性要求的任务时,可能会存在一定的欠缺;在数学、代码生成等任务上不如更大模型表现得那么稳定。
14B 模型的特点
优势:相对于 7B,其推理能力和语言理解能力有明显提升,能够较好地兼顾多种复杂任务,如数学题解析、编程任务及领域专用问答。
局限:在硬件要求上比 7B更高,需要更多计算资源支持,同时对于某些极端复杂场景,仍逊于更大规模的模型。
32B 模型的特点
优势:在复杂推理、多步逻辑和细节把控方面具有明显优势。多项基准测试(如 AIME、MATH-500、Codeforces 等)显示,32B 模型在准确性、连贯性及生成质量上均超越了 7B 和 14B 模型,能应对更高要求的专业任务。
局限:由于参数量大,部署成本和资源消耗显著上升,适合高性能服务器或云端部署,不太适合低配设备。
3. 性能与能力提升的来源
DeepSeek‑R1 系列采用了多阶段强化学习与蒸馏技术,尤其在少量标注数据条件下通过 RL 训练显著提升了模型的推理能力。
蒸馏策略:不仅使得大模型的强大推理能力得以保留,还使得即使是 7B 或 14B 的小模型也能在一定程度上获得接近大型模型的推理水平。
强化学习:特别是在数学和代码任务上,经过 RL 优化的模型(包括蒸馏版如 DeepSeek‑R1‑Distill‑Qwen 系列)在多个指标上已显示出超越同类开源模型的潜力。
4. 总结建议
若您的使用场景侧重于成本敏感、实时交互以及较低硬件要求(例如边缘设备或轻量级应用),7B 模型是一个较好的选择,其运行效率和部署便捷性都是其主要优势。
如果任务较为复杂,需要一定的推理深度(如数学题解答、代码生成或专业领域问答),且硬件条件允许,则14B 模型能在效果和资源消耗之间达到更佳平衡。
对于要求极高、任务复杂性极强的场景(例如科研、专业评测、长链推理任务),32B 模型无疑能提供最强的性能,但需要配备高端硬件或在云端进行部署以满足其资源需求。
总之,选择哪一版本应结合具体任务需求、预算和硬件配置来综合考虑。

