阿里云昨天正式发布全新推理模型 QwQ-32B ,这是一个仅含320亿参数的超大规模语言模型,却在推理能力上与拥有6710亿参数 (实际激活370亿参数)的DeepSeek-R1不相上下。通过创新性的强化学习(RL)扩展技术,QwQ-32B在数学、编程和复杂推理任务中展现出卓越表现,为大模型的高效训练与应用开辟了新路径。
技术亮点:强化学习的突破性应用
1. 强化学习(RL)的规模化探索
传统模型训练依赖预训练和微调,而QwQ-32B的核心突破在于强化学习的持续扩展 。基于Qwen2.5-32B的坚实基础,我们发现:
RL可显著提升推理能力 :在数学解题和编程任务中,RL训练能持续优化模型性能,甚至让中型模型(如QwQ-32B)与巨型模型(如MoE架构模型)一较高下。
分阶段RL训练 :
第一阶段 :聚焦数学和编程任务,利用准确性验证器 (如数学题答案校验)和代码执行服务器 (验证代码是否通过测试用例),确保输出结果的正确性。
第二阶段 :扩展至通用推理能力,通过通用奖励模型 和规则验证器 进一步优化模型的指令理解、人类偏好对齐及代理(agent)性能。这一阶段仅需少量训练步骤,即可提升综合能力,同时保持数学与编程的优势。
2. 代理能力与环境反馈的融合
QwQ-32B不仅具备强大的推理能力,还集成了代理(agent)功能 ,使其能够像人类一样“思考”:
工具利用 :模型可调用外部工具(如计算器、代码解释器)辅助推理,动态调整策略。
环境反馈适应 :根据实时反馈优化推理路径,支持多步骤、长链条的复杂问题解决。
性能表现:320亿参数对战行业标杆
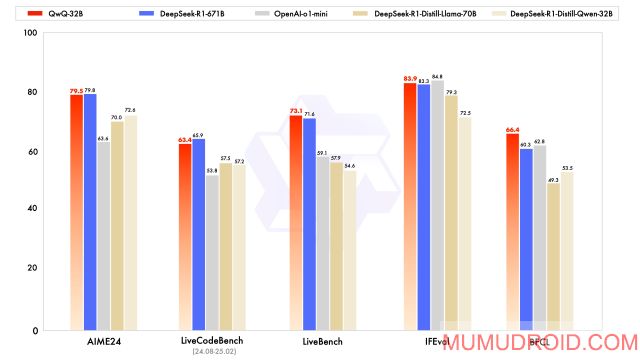
QwQ-32B在多项基准测试中展现了强劲实力,尤其在以下领域:
数学推理
超越同类模型 :在数学题解题准确率上,QwQ-32B的表现与DeepSeek-R1-Distilled-Qwen-32B和DeepSeek-R1-Distilled-Llama-70B持平,甚至优于部分更大参数量的模型。
编程能力
代码生成与执行 :通过代码执行服务器验证,QwQ-32B生成的代码在通过率上接近DeepSeek-R1,尤其在逻辑复杂度高的任务中表现稳定。
通用问题解决
指令遵循与对齐 :经过第二阶段RL训练,QwQ-32B在理解用户指令、遵循人类偏好方面显著提升,同时保持了数学与编程的高水准。
开源与开放:助力开发者与研究者
QwQ-32B完全开源,用户可通过以下渠道获取并体验:
Hugging Face :访问阿里云官方模型库,直接调用或二次开发。
ModelScope :阿里云模型开放平台提供中文友好的界面与详细文档。
Qwen Chat :通过阿里云提供的API接口,快速集成模型能力到实际应用中。
模型采用 Apache 2.0 许可证 ,支持商业与学术用途,鼓励社区共同探索强化学习与大模型结合的潜力。
未来方向:迈向通用人工智能(AGI)
QwQ-32B的发布标志着阿里云在强化学习与推理模型领域的关键一步。未来,我们将继续:
深化RL与大模型的结合 :通过更强的预训练模型与更大规模的RL训练,进一步逼近AGI目标。
探索长期推理能力 :将代理(agent)与RL深度融合,支持多步骤、长周期的复杂任务(如科学研究、战略规划)。
优化推理效率 :通过算法创新降低计算资源消耗,让高性能模型普惠更多开发者。
温馨提示:本文初稿由QwQ-32B模型生成。